
Anonymized data cannot be traced back to individuals by any means. De-identified data has personal identifiers removed but can potentially be re-identified with additional information or keys. The distinction in anonymization vs de-identification matters for GDPR, HIPAA compliance, and data security - choosing the wrong method creates legal and privacy risks.
Organizations collect massive amounts of personal data. Names, addresses, medical records, financial details, behavioral patterns - all of it creates value for research, analytics, and business operations. It also creates massive privacy and compliance risks.
Two terms dominate conversations about data protection: anonymization and de-identification. They sound similar. Regulatory documents sometimes use them interchangeably. But they represent fundamentally different approaches to protecting personal information, with different legal implications under GDPR, HIPAA, and other privacy frameworks.
The confusion creates real problems. Organizations that think they've anonymized data discover during audits that they've only de-identified i - meaning it's still subject to privacy regulations and re-identification risks. Researchers who believe they're working with anonymized datasets face compliance violations when regulators determine the data was actually only de-identified - meaning it remained personal data subject to regulatory requirements all along.
Understanding the difference between anonymization and de-identification determines whether your data protection strategy actually protects data.
Definitions of anonymized and de-identified data

Anonymized data has been processed so individuals cannot be identified by any means reasonably likely to be used. The process is irreversible - even the data controller who performed the anonymization cannot re-link the data to individuals. True anonymization requires permanent loss of any mechanism for re-identification. Once data is properly anonymized, there's no way to trace it back to specific people, even with additional information, computational power, or external datasets.
Under GDPR standards, anonymized data is no longer considered personal data. It falls outside the scope of data protection regulations because re-identification is not possible.
De-identified data has had direct personal identifiers removed - names, addresses, ID numbers - but re-identification remains possible through additional data sources, keys, or sophisticated analysis. De-identified datasets often retain indirect identifiers (quasi-identifiers) like age ranges, geographic regions, or diagnostic codes that could potentially identify individuals when combined with other information.
De-identification encompasses several methods with different characteristics. Some methods like pseudonymization are reversible - the data controller maintains a key to re-link identities when needed. Other methods like redaction are irreversible - the information is permanently destroyed with no mechanism for recovery. Redaction can serve both as a strong de-identification technique or as an anonymization method, depending on whether all re-identification risks are eliminated - including direct identifiers, quasi-identifiers, and metadata.
Under privacy regulations, de-identified data is still considered personal data if re-identification is reasonably possible.
The core distinction: Anonymization is permanent and irreversible. De-identification is reversible under certain conditions.
| Aspect> | Anonymized Data | Mitigation Strategy |
|---|---|---|
| Re-identification risk | Impossible by any reasonable means | Possible with additional data or keys |
| Reversibility | Irreversible | Reversible in controlled circumstances |
| Regulatory status (GDPR) | Not personal data | Still personal data if re-identification possible |
| Regulatory status (HIPAA)> | Beyond Safe Harbor requirements | Meets Safe Harbor or Expert Determination |
| Data utility | Often reduced significantly | Maintains more analytical value |
| Redaction | Permanent removal method | Irreversible de-identification technique |
| Use cases | Public data releases, open research | Internal analytics, controlled research |
An important cross-jurisdictional note: "de-identified" in U.S. usage roughly aligns with "pseudonymized" under GDPR terminology. Both involve removing direct identifiers while maintaining some potential for re-linkage, unlike true anonymization which eliminates that possibility entirely.
Regulatory context: How laws treat these methods differently
Privacy regulations don't just define these terms differently - they impose completely different legal obligations based on whether you use anonymization or de-identification..
GDPR (European Union)
GDPR distinguishes clearly between anonymized and de-identified data. Anonymized data is not personal data. Organizations can process it without consent, without data processing agreements, without retention limits. The full regulatory framework doesn't apply.
De-identified data remains personal data if there's any reasonable means of re-identification. This means GDPR's requirements - lawful basis, data subject rights, security measures, breach notifications - all still apply.
The practical impact: If you claim data is anonymized but regulators determine re-identification is possible, you've been processing personal data without proper legal basis. That's a violation carrying fines up to 4% of global revenue.
HIPAA (United States)
HIPAA's de-identification standards provide two methods:
Safe Harbor method: Remove 18 specific identifiers including names, geographic subdivisions smaller than state, dates (except year), phone numbers, email addresses, SSNs, medical record numbers, account numbers, and more. The organization must also have no actual knowledge that remaining information could identify individuals.
Expert Determination method: A qualified expert applies statistical or scientific principles to determine that the risk of re-identification is very small, and documents the methods used.
De-identified data under HIPAA is not Protected Health Information (PHI), which means it's not subject to most HIPAA Privacy Rule requirements. But the de-identification must be done correctly - if re-identification is possible, the data remains PHI.
HIPAA doesn't use the term "anonymization" in its regulations. The framework focuses entirely on de-identification standards.
Why jurisdiction matters
A dataset might qualify as anonymized under GDPR but only de-identified under HIPAA. Or meet HIPAA Safe Harbor requirements but fail GDPR's anonymization standard because re-identification remains theoretically possible.
Organizations operating across jurisdictions need to understand which standard applies and ensure their data protection methods meet the strictest requirements they face.
How anonymization and de-identification work
The distinction between these approaches becomes clearer when examining actual techniques.
De-identification techniques

De-identification removes direct identifiers while often preserving quasi-identifiers for analytical value:
Direct identifier removal: Strip names, SSNs, account numbers, email addresses, phone numbers -anything that directly identifies someone.
Pseudonymization: Replace identifying values with pseudonyms or tokens. A patient named "John Smith" becomes "Patient_8472." The mapping between real identity and pseudonym is stored separately, allowing re-identification when needed.
Generalization: Convert specific values to ranges. Age 34 becomes "30-40." Exact dates become months or years. ZIP code 10013 becomes "100xx."
Data masking: Hide portions of identifiers. Credit card 1234-5678-9012-3456 becomes "--****-3456."
Redaction: Irreversibly remove or obscure sensitive information by blacking out, deleting, or permanently destroying specific data points so identifiers no longer exist in the document. Unlike pseudonymization or masking, redaction is destructive—once data is redacted, the original information cannot be restored. This makes redaction particularly valuable when permanent elimination of identifiers is required without maintaining any re-identification mechanism.
These techniques reduce re-identification risk but don't eliminate it. Quasi-identifiers can be cross-referenced with external datasets to potentially identify individuals. A 34-year-old male software engineer in ZIP 10013 with a specific diagnosis might be identifiable through correlation with public records, social media, or other databases.
Anonymization techniques

Anonymization aims for permanent, irreversible de-linkage from individuals:
Aggregation: Combine individual records into summary statistics. Instead of individual patient records, report only group-level data: "250 patients aged 30-40 with diabetes." Individual-level data is destroyed after aggregation.
Data destruction: Permanently delete identifiers and quasi-identifiers without maintaining any mapping. Once destroyed, there's no key, no algorithm, no method to recover the original identities.
Noise addition: Inject random data to prevent identification while maintaining statistical properties. Each record is slightly altered so no single record can be definitively linked to a real person.
K-anonymity and differential privacy: Advanced mathematical techniques ensuring that any individual in a dataset is indistinguishable from at least K-1 other individuals, or that the presence or absence of any single individual doesn't significantly affect query results.
True anonymization trades utility for security. Aggregated data can't support individual-level analysis. Heavily noised data produces less accurate results. The question becomes: How much analytical value are you willing to sacrifice for privacy protection?
Why de-identified data isn't safe?
De-identified data faces persistent re-identification threats that anonymized data doesn't.
How re-identification happens
Researchers have repeatedly demonstrated that de-identified datasets can be re-identified by cross-referencing with public information:
A 2000 study showed that 87% of the U.S. population could be uniquely identified using just three data points: ZIP code, birthdate, and gender. These are common quasi-identifiers left in de-identified datasets.
Medical records de-identified under HIPAA Safe Harbor methods were re-identified by matching diagnosis dates, procedure codes, and geographic information with insurance claims, news articles, and social media posts.
The computational power available for re-identification attacks grows constantly. Machine learning models can identify patterns and correlations that humans miss, finding linkages between de-identified records and publicly available information.
The external data problem
De-identification assumes attackers only have access to the de-identified dataset itself. But modern re-identification attacks leverage external data sources:
- Public records (voter registrations, property records, court filings)
- Social media profiles with location, age, interests, and social connections
- Data broker databases aggregating information from hundreds of sources
- Other leaked or breached datasets containing overlapping populations
When quasi-identifiers in your de-identified dataset match quasi-identifiers in external sources, re-identification becomes possible even when you've removed all direct identifiers.
Anonymization provides stronger protection
Properly anonymized data eliminates both direct and indirect identifiers. There are no quasi-identifiers to cross-reference. No keys to discover. No algorithms to reverse.
However, even anonymization isn't always permanent. What counts as "reasonably likely means" for re-identification changes over time. A dataset properly anonymized in 2015 might become re-identifiable in 2025 as new public datasets emerge, computational methods improve, and auxiliary information becomes available. Organizations must recognize that anonymization is relative to the current state of technology and available data - not an absolute guarantee that holds forever.
Organizations should periodically reassess datasets they've classified as anonymized. What was truly anonymous five years ago may now be re-identifiable. Regular reviews confirm continued compliance with GDPR and other frameworks as the re-identification landscape evolves.
The tradeoff: anonymization often makes data unsuitable for research requiring individual-level analysis. You can't track patient outcomes over time if there's no way to link records to the same patient. You can't analyze individual behavior patterns if records are aggregated into group statistics.
Organizations must assess: Is the analytical value lost through anonymization worth the privacy protection gained?
When to use anonymization vs. de-identification
The choice depends on your use case, regulatory requirements, and risk tolerance.
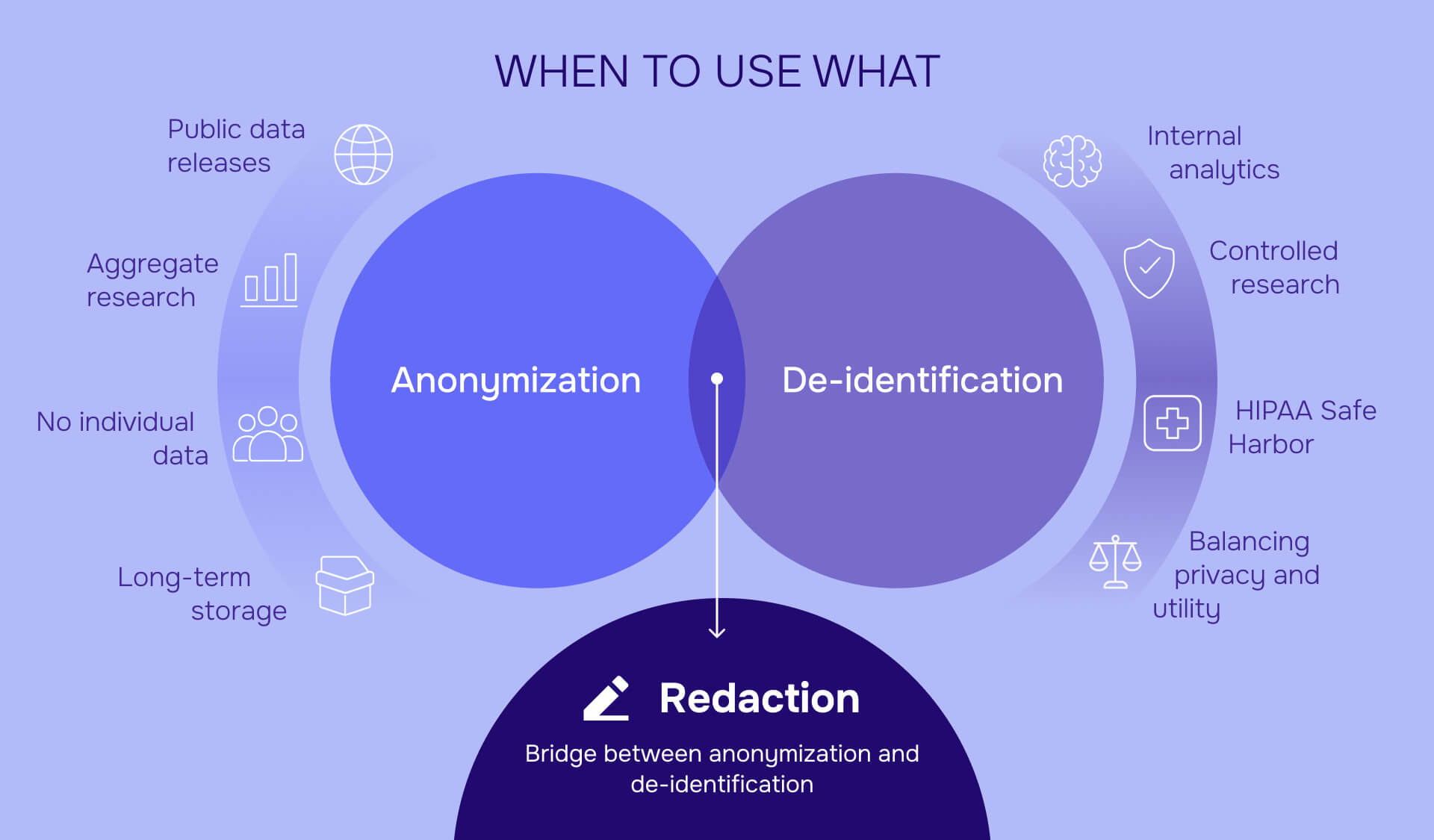
Understanding redaction's role
Redaction serves as a bridge between de-identification and anonymization. As an irreversible de-identification method, redaction permanently removes identifiers without maintaining re-identification keys. Professional redaction tools like Redactable ensure this removal is complete - deleting not just visible text but also metadata, hidden layers, and document properties that could expose identifiers.
Use anonymization when:
Publishing data publicly: Any dataset released to the public without access controls should be anonymized. Public release means unlimited re-identification attempts by unlimited parties with unlimited external data sources.
Eliminating regulatory compliance burden: Anonymized data (when done correctly under GDPR) is not personal data. You avoid consent requirements, data subject rights, breach notification obligations, and data processing agreements.
Research with no need for individual-level data: Studies focused on population trends, aggregate statistics, or group comparisons don't require individual records.
Long-term data retention: The longer you store data, the greater the re-identification risk as new external datasets emerge and analytical techniques improve. Anonymization provides protection that doesn't degrade over time.
Use de-identification when:
Internal analytics requiring individual-level data: Tracking customer journeys, analyzing patient outcomes over time, or modeling individual behaviors requires maintaining some linkage between records and individuals.
Controlled research environments: Studies where data access is restricted to authorized researchers under data use agreements, with technical and contractual controls limiting re-identification risk.
Regulatory compliance under HIPAA Safe Harbor: Healthcare organizations can share de-identified data for research while maintaining some analytical value.
Balancing privacy and utility: When you need more data utility than anonymization provides but stronger protection than identifiable data offers.
The critical question: Can you achieve your objectives with anonymized data? If yes, anonymization provides better protection. If no, de-identification may be necessary - but requires rigorous controls.
Best practices for data protection
Whether anonymizing or de-identifying, organizations should follow these principles:
Conduct privacy impact assessments
Before processing personal data, assess the risks. What identifiers exist in the data? What external datasets could be used for re-identification? What's the risk level if re-identification occurs? What controls can mitigate those risks?
Document your assessment and the rationale for choosing anonymization or de-identification.
Apply data minimization principles
Collect only the data you need. Remove unnecessary fields before anonymization or de-identification. GDPR and HIPAA both require minimizing data collection and retention.
Ask: Does this field serve our legitimate purpose? If not, delete it before processing.
Use appropriate technical controls
For de-identified data:
- Implement access controls limiting who can view the data
- Prohibit attempts at re-identification in data use agreements
- Monitor for suspicious access patterns indicating re-identification attempts
- Store any re-identification keys separately with additional security controls
- Regularly review whether de-identification remains sufficient as new data sources emerge
For anonymized data:
- Verify that re-identification is truly impossible with available techniques
- Document the anonymization methods used
- Test anonymization by attempting re-identification with realistic attack scenarios
- Consider differential privacy or k-anonymity techniques for mathematical guarantees
Establish governance and training
Privacy protections fail when staff don't understand the risks. Train employees on:
- The difference between anonymization and de-identification
- Why quasi-identifiers create re-identification risk
- Proper handling procedures for each data type
- Incident response if re-identification occurs
Create clear policies defining when each method is appropriate and who authorizes data releases.
Leverage automation for consistency
Manual anonymization and de-identification are error-prone. A single missed identifier compromises the entire dataset. Automated tools like Redactable detect and remove sensitive information consistently across thousands of documents, with audit trails showing exactly what was removed and why.
Automation reduces the risk of human error while enabling the scale required for modern data operations.
The compliance and security connection
Anonymization and de-identification aren't just privacy techniques—they're security and compliance tools.
-DeIdentification(US).jpg)
Reducing breach impact
A breach of anonymized data exposes no personal information. There's nothing to re-identify. No notification requirements under most regulations. No reputational damage from exposing customer details.
A breach of de-identified data still exposes data that could potentially be re-identified. Depending on jurisdiction and circumstances, breach notification may be required.
The Ontario Privacy Commissioner notes that strong de-identification can reduce breach risk, but only if done correctly with ongoing risk assessment.
Meeting regulatory requirements
GDPR's data minimization principle requires limiting processing to what's necessary. Anonymization demonstrates compliance by permanently removing unnecessary personal data.
HIPAA's de-identification standards provide a safe harbor for sharing health information for research while protecting patient privacy.
Choosing the appropriate method for your use case shows regulators you've implemented privacy by design - a requirement under multiple frameworks.
Creating defensible processes
When regulators or plaintiffs question your data practices, documented anonymization or de-identification processes provide evidence of good-faith privacy protection efforts.
The key: Don't just claim data is anonymized or de-identified. Document the methods used, the risk assessment performed, and the controls implemented.
Understanding the terminology matters
The confusion between anonymization and de-identification creates real risks. Organizations that misunderstand the distinction:
- Process personal data without proper legal basis, violating GDPR
- Fail to implement adequate security controls for de-identified data
- Expose themselves to re-identification attacks they didn't anticipate
- Face regulatory enforcement for inadequate data protection
Getting the terminology right means getting the legal, technical, and security implications right.
Anonymization removes all identifiers permanently and irreversibly. It provides the strongest privacy protection but reduces data utility. It takes data outside regulatory frameworks (under GDPR) but may make data unsuitable for certain analyses.
De-identification removes direct identifiers while often preserving analytical value through quasi-identifiers. It reduces but doesn't eliminate re-identification risk. It remains subject to privacy regulations when re-identification is possible.
Choose based on your needs, your regulatory obligations, and your risk tolerance. When in doubt, anonymize - you can always collect new data if you later need more detail. You can't un-breach data that was inadequately protected.
For organizations handling sensitive documents at scale, automated redaction platforms like Redactable ensure consistent, complete removal of personal identifiers across PDFs, images, and text - supporting both anonymization and de-identification workflows with full audit trails for compliance documentation.
Frequently asked questions
Anonymization permanently removes all identifiers so individuals cannot be identified by any means. De-identification removes direct identifiers but re-identification may still be possible with additional data or keys. Anonymized data is irreversible; de-identified data can potentially be re-linked to individuals.
Under GDPR, anonymized data is not personal data and falls outside regulatory requirements. De-identified data remains personal data if re-identification is reasonably possible, meaning GDPR obligations still apply including consent, data subject rights, and security measures.
Yes. De-identified data retains quasi-identifiers like age ranges, geographic regions, or diagnostic codes that can be cross-referenced with external datasets to potentially identify individuals. Studies show 87% of Americans can be uniquely identified using just ZIP code, birthdate, and gender.
De-anonymization (also called re-identification) is the process of identifying individuals from supposedly anonymous data by cross-referencing with public records, social media, data broker databases, or other datasets containing overlapping information.
HIPAA specifically addresses de-identification through Safe Harbor and Expert Determination methods. De-identified data under HIPAA is not Protected Health Information (PHI) and is not subject to most Privacy Rule requirements. HIPAA doesn't use the term "anonymization" in its regulations, focusing entirely on de-identification standards.
Use anonymized data for public releases, eliminating regulatory burden, and when individual-level analysis isn't needed. Use de-identified data for internal analytics requiring individual-level tracking, controlled research environments, and when you need to balance privacy with analytical utility.
De-identification techniques include removing direct identifiers, pseudonymization, generalization, and data masking - preserving some analytical value. Anonymization techniques include aggregation, permanent data destruction, noise addition, and differential privacy - prioritizing irreversible privacy protection over data utility.
More About
Data Privacy



Start Redacting Instantly

No credit card required
Start redacting for free
Cancel any time
Over 98% time savings with AI-powered redaction