
Your development team needs realistic customer data for testing, but using production data violates privacy regulations. Your analytics team requires detailed transaction patterns for fraud detection models, but exposing actual financial records creates compliance risks. Your offshore partners need functional datasets for integration testing, but cross-border data transfers face increasing legal restrictions.
Data masking solves these problems by transforming sensitive information into realistic but fictional alternatives that maintain business functionality. Unlike redaction which permanently removes data, or encryption which temporarily hides it, masking creates usable datasets without privacy risks.
The distinction matters because many organizations confuse masking with ineffective methods like covering data with black boxes—techniques that provide false security while leaving sensitive information recoverable. Understanding when to mask versus redact versus encrypt determines whether your data protection actually works.
How data masking transforms sensitive information?
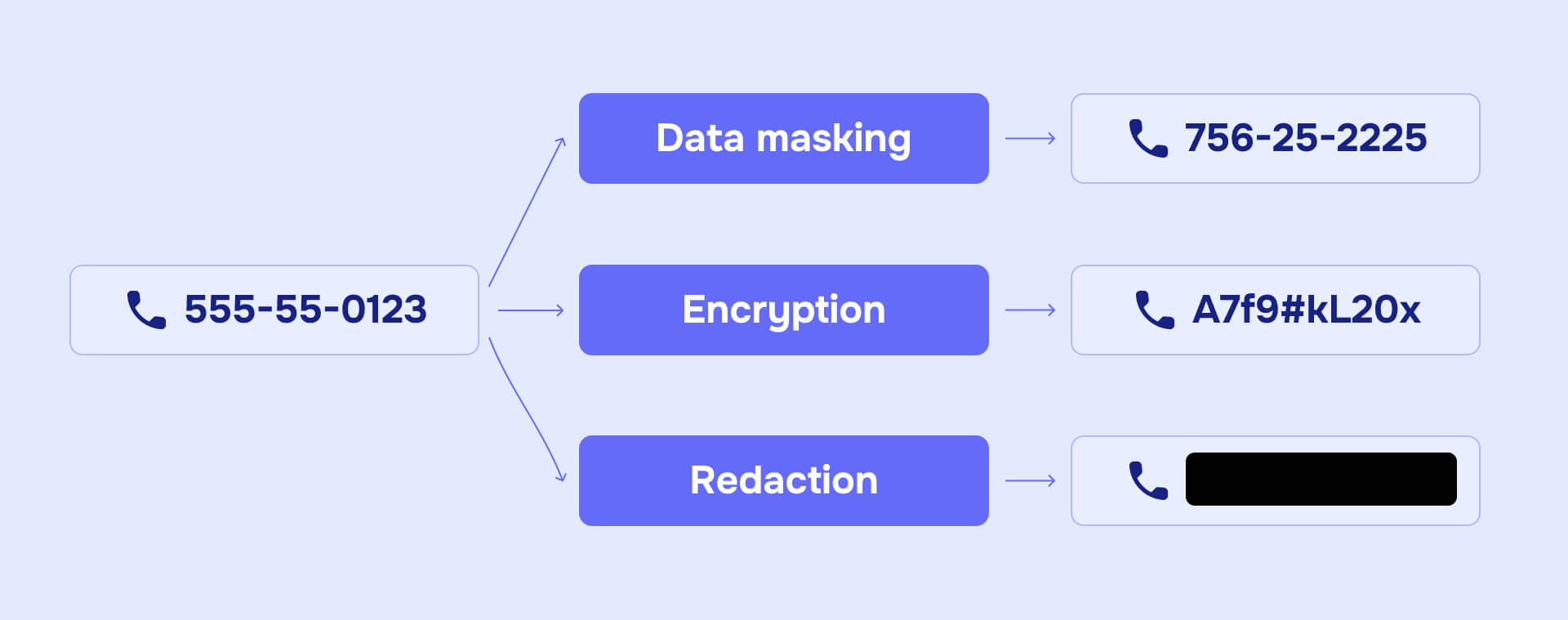
Data masking creates structurally similar but inauthentic versions of organizational data by replacing sensitive information with realistic substitutes while maintaining data utility for business operations. Unlike encryption, which temporarily hides data, data masking irreversibly transforms sensitive data while preserving its functional characteristics.
Automated redaction permanently eliminates sensitive information from documents, making it ideal for document sharing, FOIA requests, legal discovery, and compliance reporting. Redaction tools like Redactable remove personally identifiable information from PDFs, Word documents, and scanned files, ensuring sensitive data cannot be recovered even through forensic analysis.
The key distinction lies in their intended use cases: Data masking enables secure use of datasets for development, testing, and analytics by transforming data while preserving relationships and statistical properties. Redaction supports document sharing and compliance disclosure by permanently removing sensitive information that should never be accessible to recipients.
Oracle defines data masking as "process of replacing sensitive information copied from production databases to test non-production databases with realistic, but scrubbed, data based on masking rules." Microsoft emphasizes that with dynamic data masking, "the data in the database isn't changed" but appears masked to unauthorized users.
When to use data masking versus automated redaction?
Understanding when to deploy data masking versus automated redaction determines organizational success in comprehensive data protection programs. Each method serves distinct use cases with specific advantages and operational requirements.
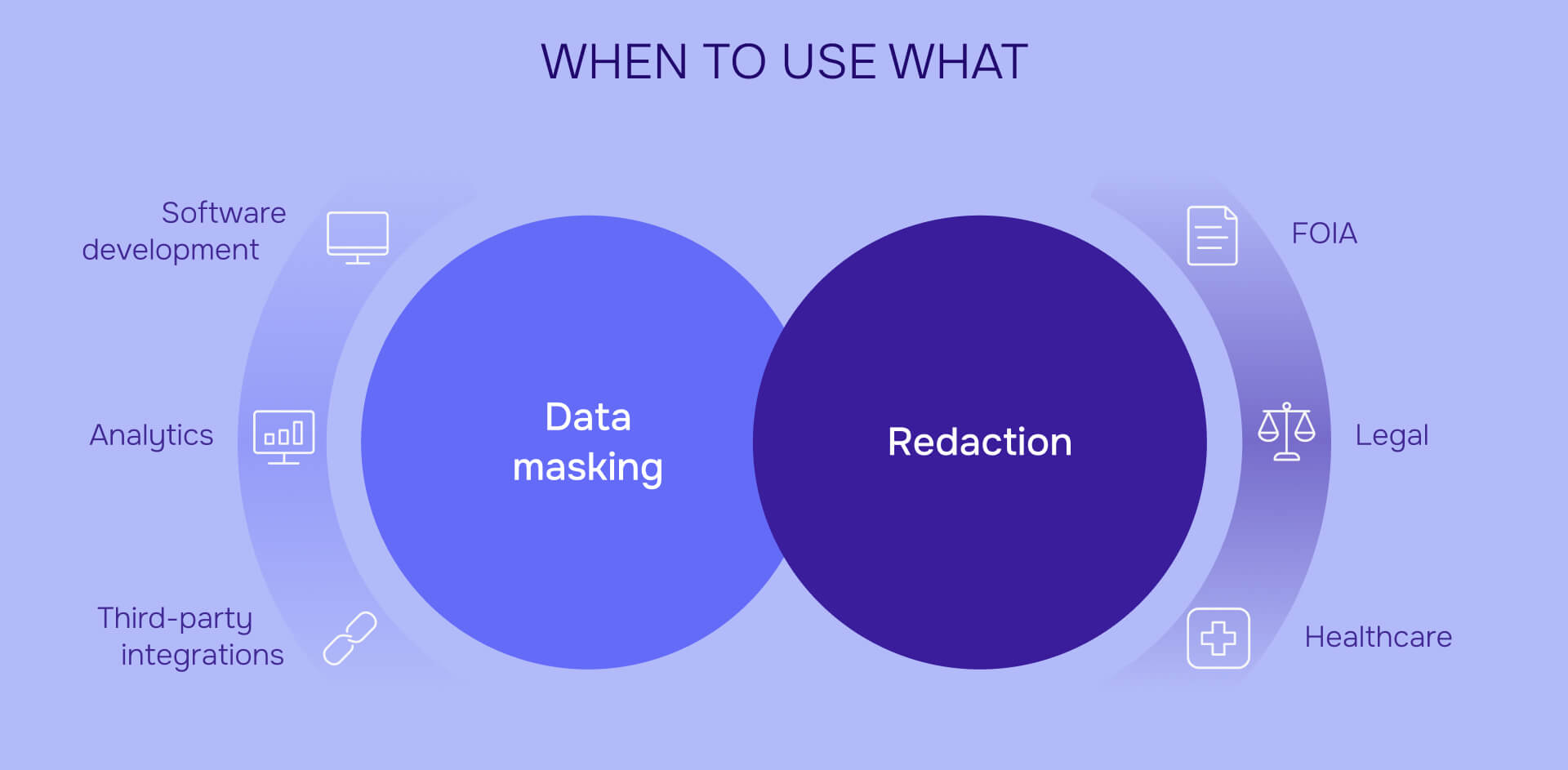
When to use data masking?
Data masking excels in scenarios requiring functional datasets while eliminating privacy risks:
- Software development and testing: Development teams need realistic data that maintains referential integrity and business logic without exposing customer information. A financial services company uses masked credit card data preserving format (4xxx-xxxx-xxxx-xxxx) and check digit algorithms while protecting actual account numbers.
- Analytics and machine learning: Data scientists require statistically representative datasets for model training. Healthcare organizations use masked patient data maintaining medical condition correlations and treatment outcomes while protecting individual identities.
- Third-party integrations: Vendor collaborations need functional data for system testing and integration validation. E-commerce platforms share masked customer profiles with logistics partners, preserving purchase behavior patterns while protecting personal information.
When to use automated redaction?
Automated redaction serves document-centric protection scenarios where information must be permanently eliminated:
- Legal discovery and litigation: Law firms redact privileged communications, social security numbers, and confidential business information from court filings. AI-powered redaction ensures complete removal of sensitive data while maintaining document readability for legal proceedings.
- FOIA and public records requests: Government agencies redact classified information, personal identifiers, and security-sensitive details from documents released under freedom of information laws. Police departments redact witness names and addresses from incident reports while preserving investigative details.
- Healthcare record sharing: Medical providers redact patient identifiers from research datasets or insurance claims while preserving clinical information. Hospitals remove names, addresses, and medical record numbers while maintaining treatment histories for medical research.
Read also: Data redaction vs. data masking
What are the three primary data masking approaches?

How static data masking provides permanent protection for non-production environments?
Static Data Masking (SDM) permanently replaces sensitive data by transforming database copies through batch processing. Organizations take production database backups, apply transformation rules during offline processing, and deploy sanitized copies to development, testing, and analytics environments.
This approach delivers high-quality masked datasets with zero runtime performance impact, making it ideal for software development, user training, and long-term analytics projects. Molina Healthcare exemplifies SDM success, reducing environment setup from hours to under 10 minutes while achieving 4PB in storage savings and maintaining full HIPAA compliance.
How dynamic data masking enables real-time protection in production?
Dynamic Data Masking (DDM) temporarily masks data during access without altering underlying databases. Database proxies intercept queries and modify result sets in real-time, returning masked data to unauthorized users while preserving original information for legitimate access.
This approach excels in production environments with complex role-based access requirements, though it introduces performance overhead requiring careful infrastructure planning.
How on-the-fly masking secures data during transfer?
On-the-fly masking transforms sensitive data during ETL processes, masking information in memory during transit from production to target systems. This approach ensures only masked data reaches destination environments without requiring intermediate storage, making it valuable for cloud migrations, third-party integrations, and cross-border data transfers.
What data masking is NOT
Data masking is frequently confused with simpler but inadequate protection methods that create false security impressions:
- Not visual covering: Unlike placing black boxes over sensitive information in documents, data masking actually transforms the underlying data values. Visual covering can be removed or bypassed, while properly masked data cannot be reversed.
- Not simple deletion: Data masking doesn't just remove sensitive fields, which would break application functionality. Instead, it replaces sensitive values with realistic alternatives that maintain data relationships and business logic.
- Not temporary hiding: Unlike encryption that can be reversed with proper keys, data masking creates permanent transformations. The original sensitive data cannot be recovered from masked versions.
Advanced masking methods balance security with data utility
Substitution delivers realistic replacement values
Substitution replaces sensitive data with realistic alternatives from lookup tables or generated values. Oracle's implementation uses hash-based partitioning functions to map original values to substitution tables while maintaining referential integrity. Employee names get replaced with names from predefined lists, ensuring realistic data that supports business logic validation while eliminating privacy risks.
Shuffling preserves statistical distributions
Shuffling rearranges existing data within columns while maintaining original value distributions and database statistics. This technique enables scenarios where salary values shuffle among employees within the same department, preserving compensation distributions while breaking individual linkages.
Format-preserving encryption maintains data structure
Format-preserving encryption transforms data while preserving original formats. Nine-digit numbers remain nine-digit numbers, supporting applications requiring specific data formats. This deterministic approach enables consistent mapping across multiple datasets while providing cryptographic protection.
How regulatory compliance drives implementation urgency?
The regulatory landscape has fundamentally shifted, with 20 U.S. states enacting comprehensive privacy laws, PCI DSS 4.0 introducing 64 new requirements, and GDPR enforcement reaching record levels with potential fines up to €20 million or 4% of global revenue, whichever is higher.

Healthcare faces strictest requirements
Healthcare organizations must protect PHI under HIPAA's Safe Harbor Rule requiring removal of 18 specific identifiers or expert determination of remaining re-identification risks. With average healthcare breach costs reaching $10.93 million, data masking provides critical protection for electronic health records, clinical research, and medical training applications.
Financial services navigate multiple frameworks
Financial institutions must comply with overlapping regulations including PCI DSS, GLBA, SOX, and emerging state privacy laws. PCI DSS 4.0's enhanced masking requirements mandate comprehensive Primary Account Number protection, while average compliance costs reach $30.9 million annually for U.S. financial institutions.
What do enterprise data masking tools cover?
The data masking market reached $767 million in 2022 with projected 14.8% annual growth driven by regulatory compliance requirements and cloud adoption.
Market leaders provide enterprise-scale solutions
K2view leads innovation with entity-based masking approaches using patented Micro-Database technology organizing data around business entities rather than table structures. This approach maintains referential integrity across heterogeneous systems while supporting complex multi-source environments.
Oracle Data Masking and Subsetting dominates Oracle-centric environments with native database integration, automated application data modeling, and pre-defined masking formats. At $230 per user and $11,500 per processor, it provides comprehensive masking within Oracle ecosystems.
IBM InfoSphere Optim serves large enterprises managing diverse legacy systems with wide database support including DB2, Oracle, SQL Server, and Teradata. Despite interface challenges, its enterprise-wide masking capabilities make it valuable for complex organizational environments.
What best practices ensure a successful implementation?

Start with comprehensive discovery and classification
Organizations cannot protect data they cannot identify. Implementing automated discovery tools using AI-enhanced scanning creates foundational data inventories with sensitivity classifications enabling risk-based prioritization and appropriate protection strategies.
Select techniques matching organizational requirements
Large enterprises benefit from comprehensive platforms handling complex multi-source environments. Oracle-centric organizations achieve efficiency through native integration, while cloud-first strategies leverage hybrid capabilities. Mid-size organizations should consider balanced approaches providing good functionality-to-cost ratios.
Implement automation and monitoring from deployment
Manual processes do not scale effectively in enterprise environments. Successful implementations embed masking into DevOps pipelines, implement policy-driven automation, and establish continuous monitoring ensuring ongoing effectiveness and compliance adherence.
Balancing data protection with functionality
Data masking represents a fundamental shift from reactive compliance to proactive privacy protection, enabling organizations to maintain regulatory adherence while preserving data utility for innovation, development, and analytics. Success requires understanding regulatory requirements, selecting appropriate technologies, and implementing systematic approaches balancing security, compliance, and operational efficiency.
For organizations handling sensitive documents alongside database operations, combining data masking with professional redaction tools creates comprehensive protection. Try Redactable for free to see how automated redaction complements masking strategies by permanently removing sensitive information from documents while maintaining their business value and readability.



