
OpenAI asked contractors to upload real work documents for AI agent evaluation and to remove sensitive information beforehand. Because modern files contain hidden data like metadata and OCR text, manual cleanup is unreliable. Secure, validated redaction is essential to prevent sensitive information from entering AI systems.
Key Takeaways
- OpenAI reportedly asked contractors to upload real work documents to evaluate AI agents, placing responsibility for redaction on individuals.
- Manual redaction often misses hidden data such as metadata, revision history, and OCR text layers.
- If sensitive information enters AI pipelines, it can create privacy, compliance, and security risks.
- Secure redaction requires permanent data removal, not visual masking.
- Validation is critical to ensure redacted documents cannot be searched, extracted, or reconstructed.
When Wired reported that OpenAI had asked contractors to upload real work documents to help evaluate its next generation of AI agents, the instruction that followed raised immediate concerns. Contractors were told to submit real PDFs, Word documents, spreadsheets, and presentations and to remove confidential or personally identifiable information before uploading.
The problem is that modern documents contain sensitive data beyond what is visible on the page. Metadata, revision history, embedded objects, and OCR text layers often remain even after manual cleanup. Asking individuals to sanitize real work files without secure redaction tools creates a high risk of unintended data exposure.
As AI systems increasingly process and learn from real documents, secure, validated redaction is essential. Without it, sensitive information can enter AI pipelines unnoticed, creating privacy, compliance, and security risks that extend far beyond a single upload.
What OpenAI reportedly asked contractors to upload?
According to Wired, OpenAI asked third-party contractors to upload real work outputs from previous or current jobs so the company could evaluate how well AI agents perform on realistic professional tasks. Contractors were instructed to remove personal information and confidential or proprietary details before submitting the files.
Follow-up reporting summarized the same initiative and highlighted concerns around intellectual property and confidentiality, noting how difficult it can be to reliably sanitize real documents:
The important detail from a redaction standpoint is simple. The burden of making documents safe to share was placed on individuals, across many file formats, without enforced validation. That approach introduces risk.
Why this is a redaction problem, not just a policy issue
There are obvious policy and legal questions here. Who owns the documents. Whether contractors are allowed to share them. Whether anonymization is sufficient to avoid violating NDAs or exposing trade secrets.
Wired reported that legal experts warned even well-intentioned contractors could unintentionally expose confidential or proprietary information despite attempts to anonymize documents.
But beneath those questions is a technical reality that often gets overlooked. Most people do not know what is actually inside a document.
A file can look clean and still contain:
- Author and organization metadata
- Tracked changes and comments
- Embedded files or images
- Hidden spreadsheet tabs
- OCR text layers behind scanned PDFs
Deleting visible names and emails does not remove these elements. That is why informal guidance like “strip out sensitive info” is not enough when documents are fed into AI systems.
Manual redaction fails at scale, even with good intentions
Manual redaction breaks down for predictable reasons. People redact what they can see. Visible identifiers get removed, while hidden layers remain.
People interpret sensitivity differently. One contractor removes company names. Another leaves them. One considers internal metrics sensitive. Another does not. People rarely validate. After editing a file, most people do not test copy and paste, inspect metadata, or attempt text extraction.
This is not negligence. It is human behavior. But it is also why manual redaction is not a reliable security control.
Why redaction matters more in the era of AI agents
AI agents are not passive tools. They are designed to read, reason over, and act on documents across workflows. That changes the risk profile.
If sensitive information enters an AI evaluation or training environment, it can be processed, stored, and reused in ways humans do not anticipate. This creates privacy, compliance, and security exposure.
Government and industry guidance increasingly emphasizes protecting data throughout the AI lifecycle. The U.S. Cybersecurity and Infrastructure Security Agency highlights the importance of securing data used in AI and machine learning systems.
Enterprise security analysis similarly warns that AI agents introduce new risks because they operate with broader autonomy and access to data. Redaction sits at the front door of these systems. It determines what data should never enter the pipeline at all.
Read also: Unredacted Epstein files show why secure redaction is mandatory, not optional
Masking is not redaction
One of the most common misconceptions about redaction is that hiding text is the same as removing it. It is not.
Data masking places a visual cover over content. The underlying data often remains. Secure redaction permanently removes sensitive data from the document structure so it cannot be recovered through copy and paste, search, text extraction, or metadata inspection.
Proper redaction must address:
- Visible text
- Hidden text layers
- OCR output
- Metadata and revision history
- Embedded objects and attachments
If any of these remain, the document is not safely redacted.

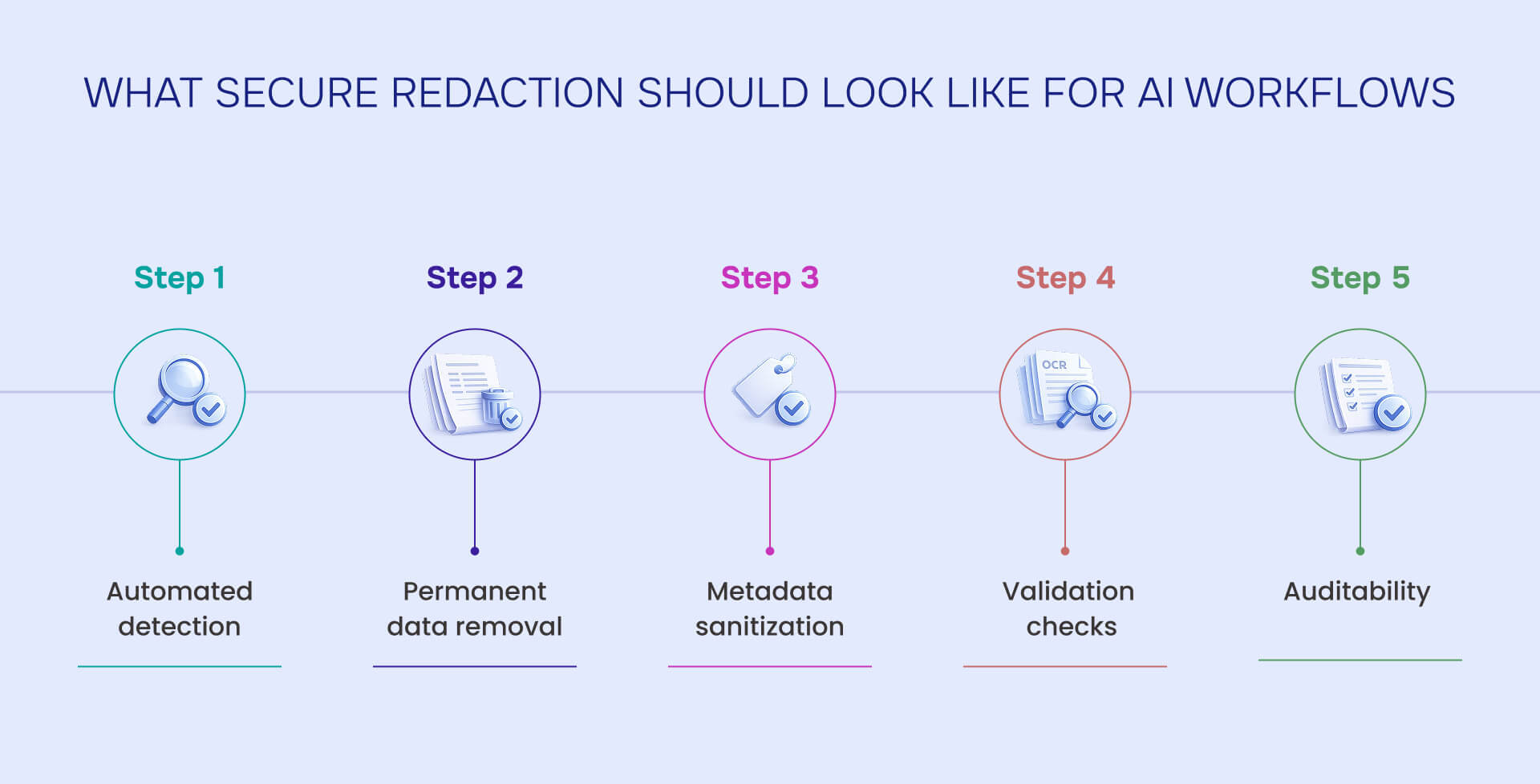
What secure redaction should look like for AI workflows
If organizations are collecting real documents for AI training or evaluation, redaction workflows should include:
- Automated detection of sensitive information such as PII, financial data, health data, and internal identifiers
- Permanent data removal from the document structure, not visual masking
- Metadata sanitization to remove authorship, comments, and revision history
- Validation checks that test copy and paste, search, extraction, and OCR behavior
- Auditability to show what was removed, why, and how it was validated
Without these steps, even well-intentioned AI initiatives risk exposing sensitive information.
Why this matters beyond OpenAI
Even if you never interact with OpenAI, this story mirrors what is already happening across organizations:
- Employees paste internal documents into AI tools
- Teams build internal AI agents on company files
- Vendors request “sample documents” for evaluation
- Contractors share work artifacts for testing systems
The moment a real document enters an AI workflow, redaction becomes a frontline security requirement.
IBM’s guidance on AI data privacy underscores this broader issue, noting that AI systems introduce new privacy risks when sensitive data is not properly protected before use.
The human cost of weak redaction
There is also a human dimension. Contractors are being asked to make judgment calls that could affect former employers, clients, and themselves. If something slips through, the consequences may fall on individuals who were simply trying to follow instructions.
Strong redaction systems protect people as much as they protect organizations.
The future of AI depends on trust
AI adoption depends on trust. Trust from users. Trust from enterprises. Trust from regulators. If people believe their real work could quietly become AI training data because redaction was superficial or inconsistent, that trust erodes.
Secure redaction is one of the simplest ways to reinforce trust while still enabling innovation.
Final thoughts
The Wired report on OpenAI contractors uploading real work documents is a signal, not a scandal. It shows where AI development is headed and where existing safeguards fall short. As AI systems become more capable, the way we prepare and protect data must evolve with them. Redaction can no longer be informal, manual, or assumed. It must be deliberate, validated, and built for scale.
In the era of AI agents, secure redaction is not optional. It is foundational. Start protecting your documents now. Try Redactable for free today!



