
If you’ve ever had to redact a document, you know the feeling: you’re trying to protect people while still being transparent. You’re trying to move fast, but not make mistakes. You’re trying to do the right thing, under pressure, with a PDF format that was never designed to make redaction easy.
Now imagine doing that with millions of pages, under the harshest public scrutiny possible.
That is why the Epstein files release turned into something bigger than a political controversy. It became a real-world case study in redaction failure, secure document redaction, and the dangers of publishing a redacted PDF that is not truly redacted.
This post breaks down the story in timeline form, including how the Epstein redacted files were released, how problems were uncovered, and why this matters for anyone handling PDF redaction, PII redaction, OCR redaction, metadata removal, and redaction validation at scale.
The Epstein files release became controversial not only for what was disclosed, but for how documents were redacted. As batches were released, critics questioned heavy redactions, missing context, and whether some "redacted PDFs" still contained recoverable data. The timeline shows why secure redaction and validation matter.
Key takeaways:
- The Epstein files were released in batches, triggering backlash over over-redaction, missing context, and delays.
- Public scrutiny raised concerns that some redactions were not technically secure, including claims of recoverable text.
- Reporting later stated the DOJ pulled files after inadequate redactions exposed victim information.
- The story highlights the difference between masking and secure PDF redaction.
- Any public release needs redaction validation, OCR handling, and metadata sanitization to prevent leaks.
How the Epstein redacted files were released and uncovered: A Complete timeline
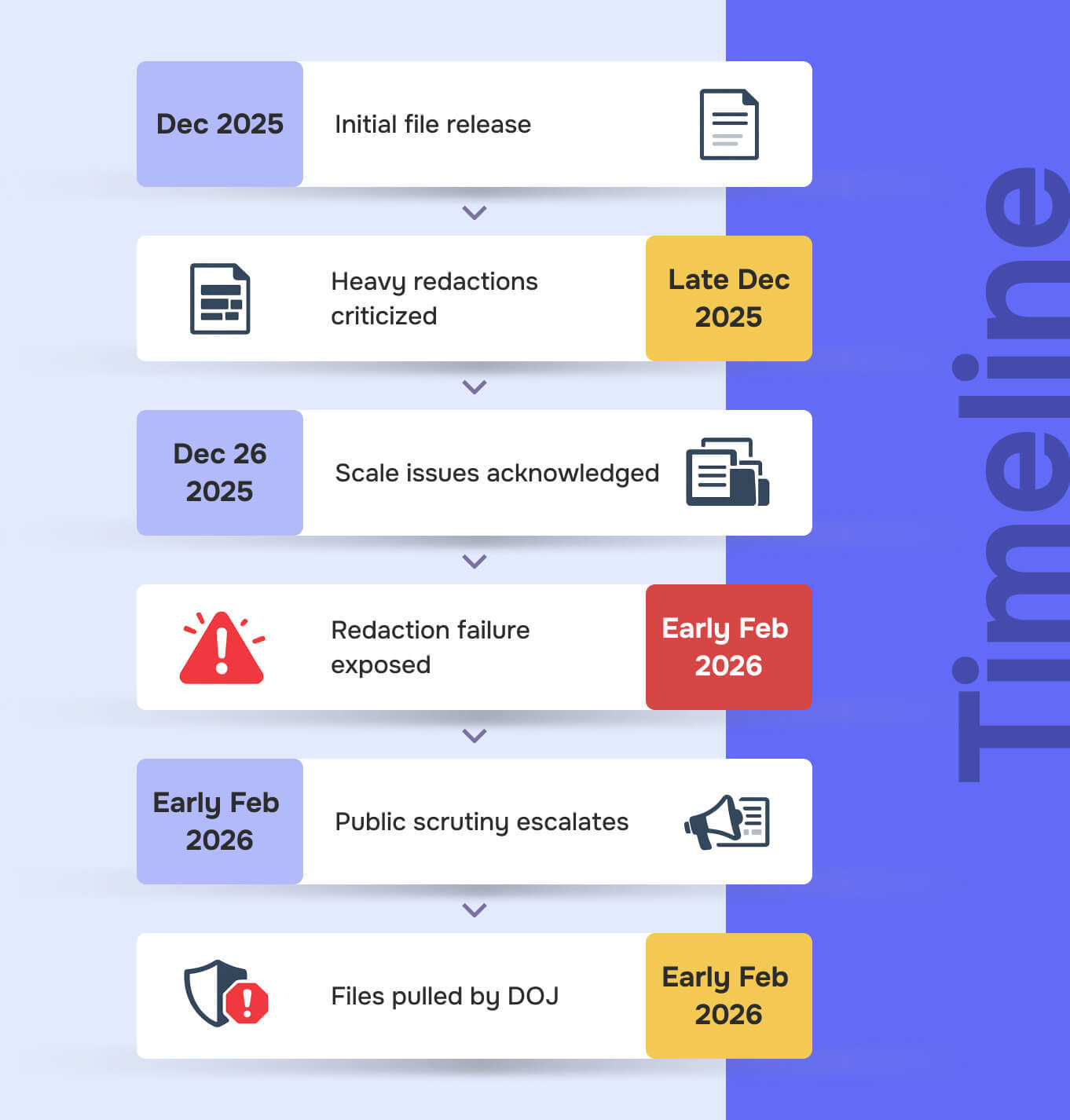
1) December 2025: The first releases drop and criticism begins immediately
The initial Epstein files releases were always going to be sensitive. The documents involved victims, witnesses, and private individuals. Redaction was expected. But as the first batches went public, criticism began almost immediately. Not just about what was missing, but about how aggressively information had been blacked out. PBS NewsHour reported that lawmakers criticized the DOJ’s heavily redacted release and questioned whether the agency was meeting transparency expectations. CBS News similarly reported that hundreds of pages were entirely blacked out, leaving readers wondering whether the release was meaningful or simply symbolic.
This was the first moment the public learned a key truth about redaction: people do not just judge what is hidden. They judge the competence of the hiding. When redaction is too heavy, people assume a cover-up. When redaction is too light, people assume negligence. Either way, the redaction process itself becomes the story.
2) Late December 2025: DOJ says there is more material than expected
As criticism grew, the DOJ emphasized the scale of what remained. The review process was not done. More documents were being found, and more redaction would be needed before release.
CBS live updates described DOJ statements that additional potentially relevant materials had been uncovered and that more time would be required to review and redact at scale.
This is where redaction becomes an operational problem. At small scale, teams can redact manually and catch mistakes. At large scale, mistakes are guaranteed unless the workflow includes:
- standardized rules
- automated detection of sensitive content
- consistent redaction logic across documents
- validation checks that prove nothing is recoverable
3) December 26, 2025: Viral claims that redacted text could be revealed
Then came the most damaging development: claims that some “redacted” Epstein files could be unredacted.
The allegation was simple. Some people said they could copy and paste “redacted” text and see what was hidden. If true, that would mean the redaction was not secure. It would mean black boxes were used as visual masks without removing the underlying data.
Snopes investigated these claims and found at least one released document where “redacted” text could be viewed via copy and paste, while clarifying that this did not apply to every file.
This is the most important redaction concept in the entire Epstein files timeline: Masking is not redaction.
Masking covers content visually. The data can still exist in the PDF structure. That data can sometimes be recovered through:
- copy and paste
- PDF text extraction tools
- conversion tools
- accessibility layers
True secure PDF redaction removes the sensitive content from the internal PDF content stream so it cannot be recovered.
Read also: Redacted Epstein files: Here is what went wrong (December 2025)
4) Early February 2026: Millions more documents released, but controversy grows
By early February, the DOJ released additional batches. Instead of settling the controversy, the new releases intensified it. More files meant more redaction questions.
The Washington Post reported that the DOJ released over 3 million documents, but that the rollout remained chaotic and many questions remained due to redactions and missing context.
PBS NewsHour also discussed what was revealed and what remained redacted, reinforcing that redaction decisions were shaping how the public interpreted the entire release.
Why this matters: inconsistency becomes a leak vector
When you release huge document sets, inconsistency becomes dangerous.
Even if every individual PDF looks “fine,” the public can cross-reference:
- names redacted in one file but not another
- partial identifiers
- dates and context clues
- repeated phrases
That is how people reconstruct what you meant to hide.
5) February 3, 2026: DOJ pulls files after inadequate redactions exposed victim information
This is the turning point where the story becomes more than controversy. It becomes harm.
The Associated Press reported that the Justice Department pulled thousands of documents and media files after inadequate redactions exposed sensitive victim information, and officials cited errors while outlining changes to protocols.
People.com reported survivors condemning the release as incomplete and distressing, including concerns about victim names being revealed while other identities remained protected.
Why this matters: Redaction failure is irreversible
This is the nightmare scenario.
When redaction fails in a public release:
- the data spreads instantly
- copies persist forever
- victims lose privacy
- the agency loses trust
- legal and compliance exposure increases
Redaction is not a “design detail.” It is a safety measure.
6) February 2, 2026: Lawmakers demand full compliance and clearer process
As the controversy grew, lawmakers pushed for clearer compliance with the transparency law and better explanations of the DOJ’s process. Roll Call reported lawmakers pursuing full compliance with the Epstein transparency law and scrutinizing the DOJ’s approach.
In a high-stakes disclosure, you need to answer questions like:
- What was redacted and why?
- What policy required the redaction?
- Who reviewed it?
- What validation checks were performed?
If you cannot answer those questions, trust collapses.
What this timeline proves about redaction?
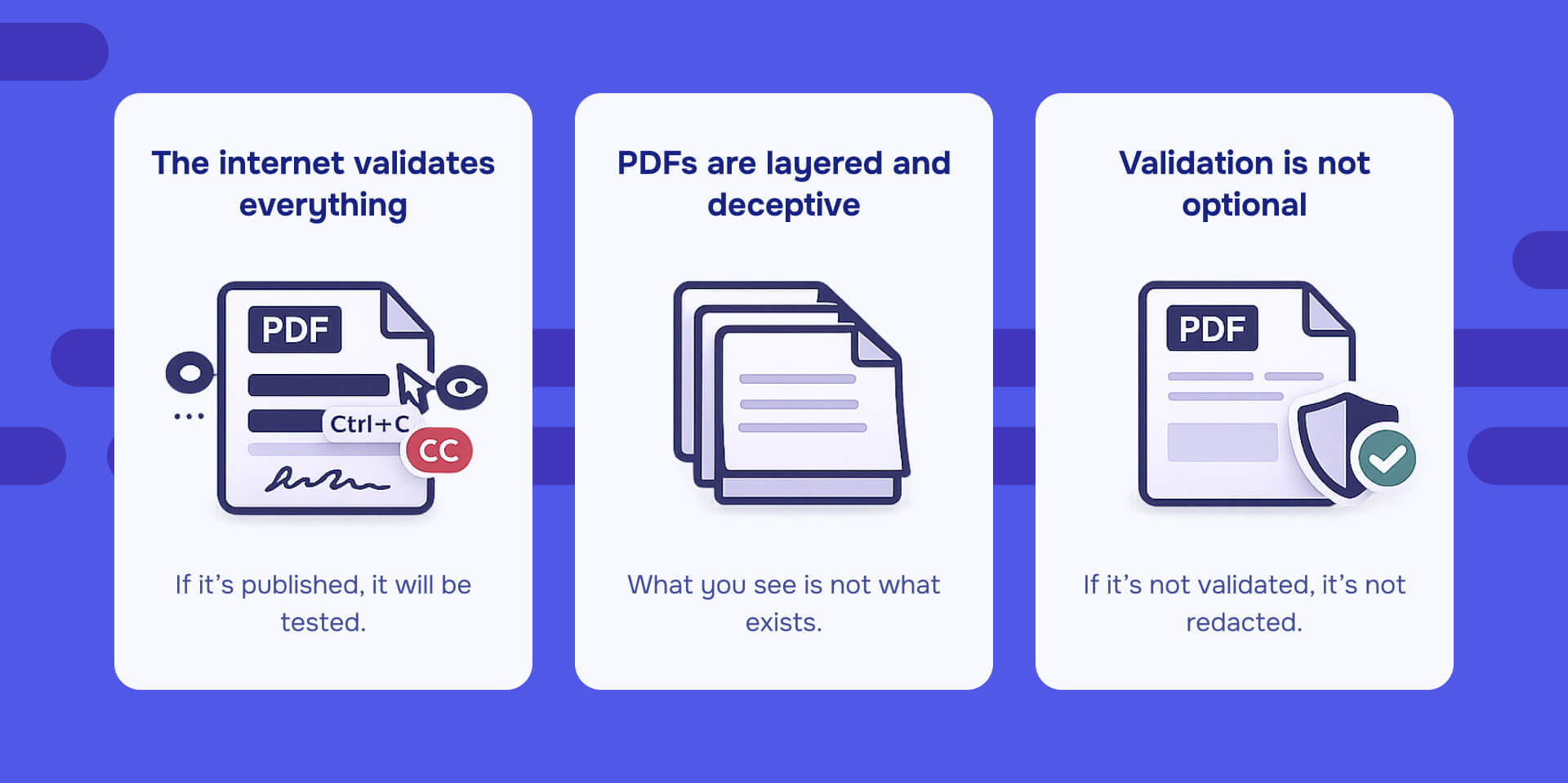
The Epstein files timeline shows three uncomfortable truths about redaction in 2026:
1) The internet validates everything. If you publish a redacted PDF, assume thousands of people will try to break it.
2) PDFs are layered and deceptive
A PDF can look redacted and still contain:
- underlying text objects
- OCR text
- metadata
- embedded files
3) Validation is not optional
The only defensible redaction workflow includes redaction validation, including tests for:
- copy/paste leakage
- text extraction leakage
- OCR leakage
- metadata leakage
Secure redaction checklist (what should have happened)
If you are releasing sensitive documents, especially public records, investigations, FOIA responses, or court materials, secure redaction should include:
- Permanent data removal from the PDF structure (not just black boxes)
- OCR redaction for scanned and searchable PDFs
- PII redaction for names, emails, phone numbers, addresses, IDs
- Metadata removal including author fields, comments, revision history
- Redaction validation across every page, every file
- Consistency checks across the full document set
- Audit logs for defensibility and oversight

Final takeaway
The Epstein files release did not just become controversial because of what was disclosed. It became controversial because redaction itself became unreliable in the public’s eyes. And once that happens, the damage is not just reputational. It can be personal, permanent, and harmful.
In 2026, secure redaction is not about black boxes. It is about permanent data removal, metadata sanitization, OCR handling, and validation that proves sensitive information is truly gone.



