
Not all data breaches carry the same weight. Losing a marketing email list triggers different consequences than exposing medical diagnoses, full credit card numbers, or whistleblower identities. Understanding which types of sensitive information you handle - and the legal obligations attached to each - determines whether your response is a minor incident report or a career-ending regulatory penalty. This guide breaks down the four core categories of sensitive data (PII, PHI, PCI, and confidential business information), shows you what separates "ordinary" from "high-impact" data, and explains exactly when redaction stops being optional.
The difference between a contained data incident and a catastrophic breach often comes down to one question: what kind of information was exposed?
A leaked list of newsletter subscribers might cost you some trust and require disclosure. A spreadsheet containing Social Security numbers, cancer diagnoses, or full payment card data can trigger federal investigations, million-dollar fines, and class-action lawsuits. Same "data breach" label, radically different outcomes.
Here's what most organizations miss: NIST explicitly states that "all PII is not created equal." Federal agencies must classify personally identifiable information as low, moderate, or high impact based on potential harm. GDPR takes it further, flatly prohibiting the processing of "special categories" like health data, biometrics, and political opinions unless narrow conditions are met. HIPAA defines 18 specific identifiers that transform health information into protected health information, triggering strict safeguards and penalties that can reach or exceed $1.5 million per violation category per year, with caps adjusted periodically by HHS.
By the end of this article, you'll be able to recognize the main types of sensitive data in your systems, understand which laws and contracts attach to them, and know when redaction becomes mandatory - not just best practice.
What counts as sensitive data and who decides?
Sensitive data is any information whose unauthorized access, use, or disclosure could cause harm to individuals or organizations. That definition comes from NIST's focus on confidentiality impact and GDPR's standard of "likely to result in high risk to rights and freedoms."
But here's the nuance that trips up most teams: sensitivity is context-dependent.
An email address on a public blog post carries low risk. The same email address in a database of domestic violence survivors, HIV patients, or confidential informants becomes high-impact data requiring encryption, access controls, and aggressive redaction before any disclosure.
This is why data classification frameworks distinguish between:
- Intrinsic sensitivity: Data that's inherently risky regardless of context (biometric templates, genetic markers, full Social Security numbers)
- Sensitivity by linkage: Seemingly innocuous data that becomes identifying when combined (date of birth + ZIP code + gender can re-identify individuals in 87% of cases)
The practical consequence: you can't treat all information the same way. A one-size-fits-all approach to data protection leaves you exposed where it matters most and wastes resources on data that carries minimal risk.
The four core types of sensitive data
1. Personally identifiable information (PII)
PII is information that can distinguish or trace an individual's identity, either directly or through linkage with other data. This is the broadest category of sensitive information and the foundation for most privacy regulations.
Direct vs. indirect identifiers
Direct identifiers immediately reveal identity on their own:
- Full name combined with Social Security number
- Driver's license or passport number
- Biometric records (fingerprints, retinal scans, voice prints)
- Full-face photographs tagged with names
Indirect identifiers become identifying in combination:
- Date of birth + five-digit ZIP code
- Gender + race + occupation + company size
- Timestamps + location patterns from mobile devices
- Purchase history combined with demographic data
Here's the compliance trap: regulations don't just cover direct identifiers. HIPAA's "safe harbor" de-identification standard requires removing 18 categories of identifiers, many of which are indirect. GDPR explicitly addresses "identifiable" individuals, not just "identified" ones.
"Ordinary" vs. sensitive PII

Not all PII carries the same risk. NIST explicitly states that organizations should rate PII as low, moderate, or high impact depending on potential harm if exposed:
- Low impact: Business contact information, general demographic data already public
- Moderate impact: Personal email addresses, dates of birth, employment history
- High impact: Government IDs, financial account numbers, biometric data, detailed behavioral profiles
The distinction matters for technical controls. High-impact PII should be encrypted at rest and in transit, restricted to need-to-know access, and permanently redacted from any documents leaving your secure environment - not just visually masked with black boxes.
2. Health and genetic data (PHI and special category data)
Health information sits at the top of the sensitivity hierarchy because exposure can lead to discrimination, denial of insurance, employment consequences, and profound privacy violations.
PHI under HIPAA
Protected Health Information (PHI) is individually identifiable health information held by a covered entity or business associate, in any form -electronic, paper, or oral - relating to:
- Past, present, or future physical or mental health conditions
- Provision of healthcare to an individual
- Payment for healthcare services
What makes health data "protected" under HIPAA? The presence of any of 18 specific identifiers attached to health information:
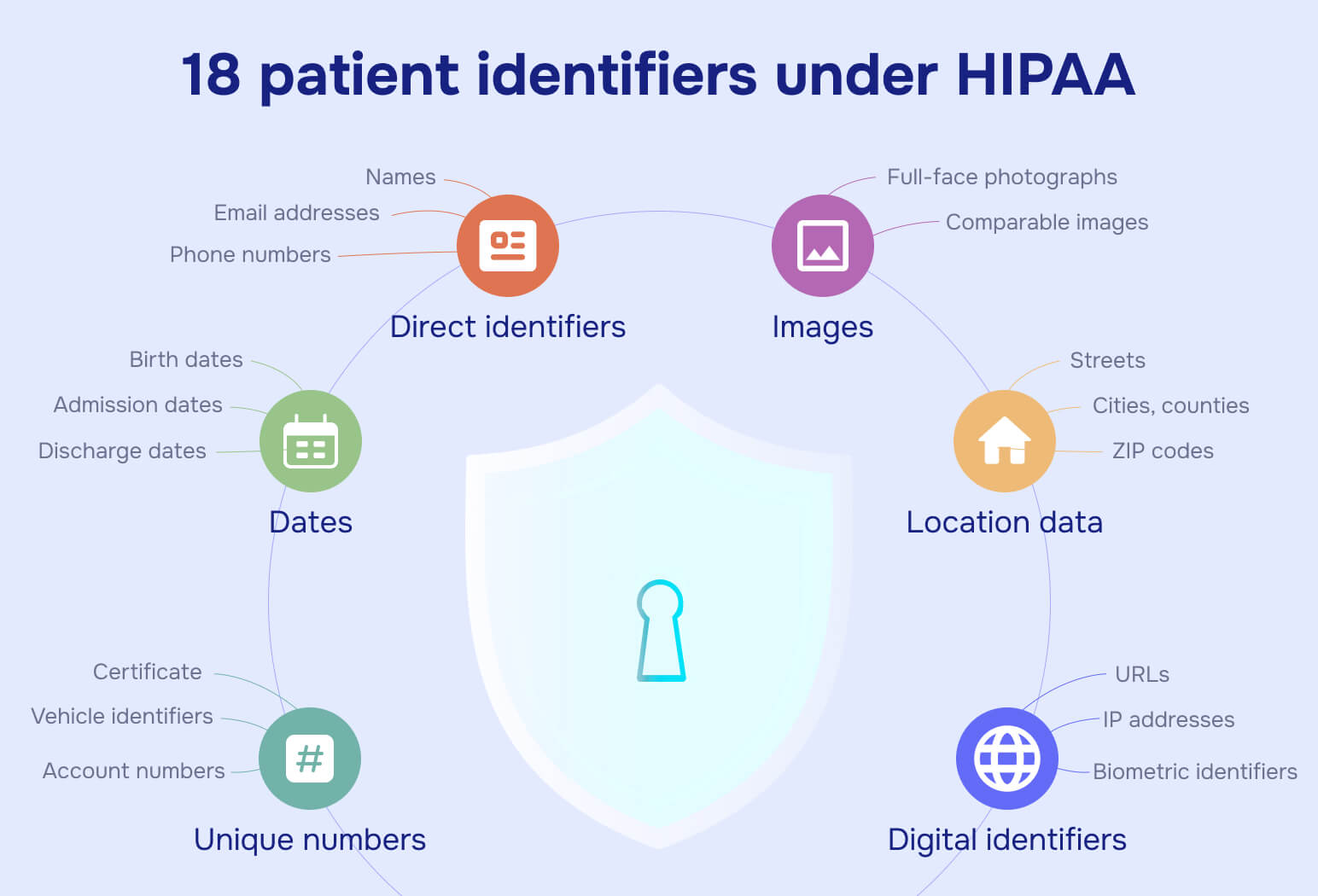
- Names
- Geographic subdivisions smaller than a state (street addresses, cities, counties, ZIP codes)
- Dates (birth, admission, discharge, death, or exact ages over 89)
- Phone numbers
- Fax numbers
- Email addresses
- Social Security numbers
- Medical record numbers
- Health plan beneficiary numbers
- Account numbers
- Certificate or license numbers
- Vehicle identifiers and serial numbers
- Device identifiers and serial numbers
- Web URLs
- IP addresses
- Biometric identifiers
- Full-face photographs
- Any other unique identifying number, characteristic, or code
The penalties for mishandling PHI are severe. Violations are tiered based on knowledge and intent, with annual maximum penalties reaching $1.5 million per violation category. And unlike many regulations, HIPAA's enforcement arm (OCR) has shown consistent willingness to investigate and fine organizations of all sizes.
Health data under GDPR
GDPR Article 9 classifies "data concerning health" and genetic or biometric data used for unique identification as "special categories" that are generally prohibited to process unless specific conditions are met (explicit consent, vital interests, employment law, substantial public interest, etc.).
This creates a compliance gap that catches US-based companies: HIPAA covers healthcare providers, health plans, and their business associates. GDPR covers anyone processing health data of EU residents, regardless of industry. An HR department handling employee medical leave records, a fitness app tracking biometric data, or a research institution analyzing genetic samples all fall under GDPR's stricter standard.
The redaction implication: health records released for research, shared in litigation discovery, or disclosed in response to subject access requests must be rigorously de-identified. Visual redaction tools that leave underlying text searchable don't meet the standard. You need permanent removal of identifiers and metadata.
3. Financial and payment card data (PCI)
Financial information carries dual risk: direct monetary theft and long-term fraud enabled by stolen credentials and account details.
Cardholder data under PCI DSS
The Payment Card Industry Data Security Standard (PCI DSS) defines two critical categories:
Cardholder data includes:
- Primary Account Number (PAN) – the full card number
- Cardholder name
- Expiration date
- Service code

Sensitive authentication data (which must never be stored after authorization):
- Full magnetic stripe data
- CAV/CVC/CVV/CID security codes
- PINs and PIN blocks
Here's the enforcement reality: PCI DSS isn't a law, it's a contractual obligation enforced by payment brands (Visa, Mastercard, etc.). Non-compliance can result in fines that can reach tens of thousands of dollars per month, higher transaction fees, and even loss of payment processing privileges.
Why partial exposure still matters
Even truncated or masked card data combined with other information creates fraud risk. A support ticket showing the last four digits of a card number, plus the cardholder's full name, email address, and billing ZIP code, gives bad actors enough information for social engineering attacks or account takeovers.
This is why PCI DSS requires strict controls on cardholder data in all forms: payment processing logs, customer service screenshots, emailed receipts, and CSV exports. If you're sharing documents that might contain payment information, permanent redaction with guaranteed metadata removal isn't optional.
Special category and high-risk personal data under GDPR
Beyond health data, GDPR Article 9 identifies several special categories of personal data that require exceptional handling:
- Racial or ethnic origin
- Political opinions
- Religious or philosophical beliefs
- Trade union membership
- Genetic data
- Biometric data for unique identification (facial recognition, fingerprints)
- Data concerning sex life or sexual orientation
Why the heightened protection? Because misuse can cause discrimination, denial of services, persecution, physical harm, or social stigma.
Real-world examples:
- Political donation records used to target individuals for harassment
- Facial recognition logs that reveal attendance at protests or religious services
- Employment records showing union membership in anti-union jurisdictions
- Healthcare data revealing HIV status, mental health treatment, or reproductive history
These aren't theoretical concerns. Companies have faced multi-million euro fines for inadequate protection of special category data, often because redaction workflows failed to remove metadata or relied on visual masking that left sensitive information embedded in file properties.
4. Confidential business and operational data
Not all sensitive data is personal information. Organizations also handle business-sensitive data that, while not regulated under privacy laws, carries significant competitive and legal risk.
Trade secrets and commercially sensitive information
Trade secrets are information that derives independent economic value from not being generally known and is subject to reasonable secrecy measures. Examples include:
- Proprietary source code and algorithms
- Pricing strategies and customer lists
- Manufacturing processes and formulas
- Negotiation strategies and M&A documents
- Security architecture and incident response playbooks
- Competitive intelligence and market analysis
Exposure doesn't just harm competitive position - it can eliminate trade secret protection entirely under the law. Once disclosed without adequate confidentiality measures, trade secret status may be lost permanently.
Internal classification levels
Many organizations adopt classification frameworks inspired by government and NIST models:
- Public: Information intended for public disclosure (marketing materials, published reports)
- Internal: Information for internal use but not highly sensitive (general policies, org charts)
- Confidential: Information that would cause significant harm if disclosed (business strategies, employee data, contract terms)
- Restricted: Information that would cause severe harm if disclosed (authentication credentials, encryption keys, security vulnerabilities, customer financial data)
Restricted data often includes technical secrets that must never appear in logs, support tickets, or code repositories without redaction:
- Database connection strings with embedded credentials
- API keys and OAuth tokens
- Encryption keys and certificates
- Privileged account passwords
- Security vulnerability details before patches are deployed
The compliance gap: these items might not fall under HIPAA, PCI DSS, or GDPR, but contractual obligations (NDAs, service agreements) and liability exposure (negligence claims, trade secret theft) still require strict handling.
Bringing it together: A sensitivity decision matrix
Use this framework to assess your data:
| Data Type | Examples | Impact if Exposed | Key Obligations |
|---|---|---|---|
| Basic PII | Names, business emails, phone numbers | Low to moderate: spam, phishing, minor privacy violation | State breach notification (thresholds vary), GDPR lawful basis |
| Sensitive PII | SSN, driver's license, passport, biometric data | High: identity theft, fraud, physical danger | NIST high-impact controls, mandatory breach notification, GDPR data protection by design |
| PHI | Medical records, diagnoses, lab results, genetic data with identifiers | High: discrimination, insurance denial, stigma | HIPAA Security Rule, GDPR Article 9 restrictions, breach notification to OCR and individuals |
| PCI cardholder data | Full card numbers, names, expiry dates, CVV codes | High: financial fraud, card replacement costs, brand penalties | PCI DSS compliance, encryption, immediate post-authorization purge of sensitive auth data |
| GDPR special categories | Political views, union membership, sexual orientation, religious beliefs | High: persecution, discrimination, social harm | GDPR Article 9 legal basis required, explicit consent or substantial public interest justification |
| Trade secrets | Source code, pricing models, security runbooks, negotiation strategy | Severe: competitive disadvantage, loss of legal protection | NDA enforcement, access controls, redaction before litigation or M&A disclosure |
| Security credentials | Passwords, API keys, encryption keys, database connection strings | Severe: system compromise, data breach, lateral movement by attackers | Immediate rotation if exposed, never store in clear text, redact from all logs and tickets |
This isn't just a classification exercise. The matrix tells you where to focus security resources, which documents need redaction workflows before sharing, and which data types trigger legal notification obligations if a breach occurs.
Where redaction becomes non-negotiable
Understanding data types is step one. Step two is knowing when you must permanently remove sensitive information from documents, not just restrict access.
Redaction vs. access control vs. minimization
These are distinct controls:
- Access control: Limiting who can see data (role-based permissions, encryption, secure systems)
- Data minimization: Not collecting or keeping data you don't need (GDPR storage limitation principle)
- Redaction: Permanently and irreversibly removing sensitive elements from a document that must exist or be shared
The critical distinction: access controls can be bypassed by insiders, breaches, or subpoenas. Redaction ensures sensitive data is gone, even if the document itself falls into the wrong hands.
When redaction is required, not recommended
HIPAA scenarios:
- Medical records released to researchers under limited data sets
- PHI in litigation discovery (privilege logs, expert witness materials)
- Patient requests for copies of their records when third-party information must be protected
- Responding to subpoenas where only specific information is relevant
PCI DSS scenarios:
- Transaction logs shared with auditors or investigators
- Customer support tickets containing card data screenshots
- Chargeback documentation packages sent to acquiring banks
- System troubleshooting when payment terminals or processing code is involved
GDPR special category scenarios:
- Subject access requests where documents contain third-party special category data
- HR investigation files shared with regulators or in employment tribunals
- Research datasets derived from biometric, health, or political activity data
- Whistleblower reports submitted to authorities (protecting whistleblower identity)
Trade secret and confidential business scenarios:
- Source code samples in patent litigation or copyright disputes
- Vendor due diligence packages during M&A with competitive sensitive information
- Security incident reports shared with law enforcement (protecting infrastructure details)
- Financial audit documentation containing proprietary pricing or margin data
Read also what went wrong with Epstein file redactions
Why visual masking sensitive data doesn't work

Here's the dangerous myth that persists: drawing black boxes over sensitive text in a PDF or blurring a screenshot protects you.
It doesn't.
Visual redaction tools often leave the underlying text intact and searchable. PDF metadata preserves original file creator information, revision history, and comments. Screenshots contain EXIF data with device identifiers and timestamps. Even "flattened" PDFs can leak information through font embedding, hidden layers, or objects outside the visible page boundaries.
Compliance frameworks explicitly reject cosmetic redaction:
- NIST SP 800-122 warns that "masking" doesn't meet de-identification standards because data remains in the file
- HIPAA's safe harbor method requires complete removal of 18 identifier types, not visual hiding
- GDPR's principle of data minimization means sensitive data must be deleted, not merely obscured
Permanent redaction means:
- Removing text and images from the actual document structure, not overlaying black boxes
- Stripping all metadata (author, creation date, edit history, geolocation, device identifiers)
- Eliminating hidden data (transparent objects, covered text, content outside page boundaries, form field values)
- Producing a clean file where sensitive information is gone, not hidden
Building a defensible sensitive data inventory
Theory is useful. Implementation wins compliance audits and prevents breaches.
Step 1: Identify where each sensitive data type lives
Map your systems to data categories:
- Customer Relationship Management (CRM): Names, contact info, interaction history, sometimes SSNs or dates of birth (PII, potentially sensitive PII)
- Electronic Medical Records (EMR): Full PHI under HIPAA, special category health data under GDPR
- Payment processing systems: Cardholder data under PCI DSS (PANs, names, expiry dates)
- HR information systems: Employee SSNs, medical leave records (PHI), possibly union membership or disability status (special category data under GDPR)
- Support ticketing systems: Often contain leaked sensitive data in attachments, screenshots, or pasted logs (PII, PCI, sometimes PHI or credentials)
- Document management / shared drives: Contracts (confidential business data), NDAs (trade secrets), audit reports (restricted operational data)
- Source code repositories: API keys, database passwords, customer data in test fixtures (security credentials, PII)
- Email and collaboration tools: Unstructured data mixing all categories, often with no systematic classification
Step 2: Classify by sensitivity and impact
For each data location, apply the decision matrix:
- What's the harm if this data is exposed? (Identity theft, fraud, discrimination, business loss)
- What regulations or contracts apply? (HIPAA, PCI DSS, GDPR, CCPA, NDAs, trade secret law)
- What's the organization's risk appetite and industry expectation? (Healthcare and finance face stricter scrutiny than retail or media)
Rate each data set using NIST's impact level framework:
- Low impact: Inconvenience or minor embarrassment if disclosed
- Moderate impact: Significant financial loss, reputation damage, or emotional distress
- High impact: Severe physical, financial, or reputational harm; identity theft; blackmail; discrimination; loss of trade secret protection
Step 3: Map controls to sensitivity levels
For each classification, decide:
- Can it be deleted? If you don't need it, data minimization is the strongest protection.
- Must access be restricted? Encryption, role-based access, and audit logging for moderate and high-impact data.
- Must it be redacted before sharing? Any external disclosure, litigation, public records requests, or cross-border transfers of high-impact data require permanent redaction, not just access controls.
Document your decisions. Classification without a control mapping is just paperwork. Control mapping without enforcement is negligence.
Step 4: Establish redaction standards for each category
Create specific rules:
- PII in public records responses (FOIA): Redact names, addresses, SSNs, dates of birth; apply relevant exemption codes
- PHI in research data: Remove all 18 HIPAA identifiers or apply expert determination for de-identification
- Cardholder data in support tickets: Redact full PANs (keep last 4 for reference if necessary), remove CVV codes entirely, mask expiry dates
- Special category data in HR files: Redact health conditions, religious references, union membership, and sexual orientation in files shared outside HR
- Trade secrets in litigation: Redact proprietary algorithms, customer lists, pricing formulas; produce sanitized versions under protective order
- Security credentials in logs: Never share authentication tokens, API keys, passwords, or encryption keys; redact before log aggregation or SIEM ingestion
Make these standards mandatory in workflows. "Best effort" redaction fails under regulatory scrutiny.
Key takeaways: sensitivity is about predicting harm, then preventing it
Sensitive data isn't a monolithic category. The four core types - personally identifiable information, health data, payment card information, and confidential business data - each carry different legal obligations, breach penalties, and technical protection requirements.
Here's what determines whether you face a compliance audit or a federal investigation:
- Know your impact levels. Not all PII is equal. A leaked business email is not the same as an exposed Social Security number. Use NIST's low/moderate/high framework to prioritize controls.
- Understand your legal exposure. HIPAA, PCI DSS, GDPR Article 9, and trade secret laws don't overlap neatly. An organization handling healthcare payments might face all four regulatory regimes simultaneously.
- Recognize when redaction is mandatory. Access controls fail. Data minimization isn't always possible. When sensitive documents must be shared - in litigation, FOIA responses, research, or audits - permanent redaction is the only defensible protection.
- Reject visual masking. Black boxes over text, blurred screenshots, and strikethrough formatting don't remove data. They hide it, poorly. Metadata, hidden layers, and searchable text remain exploitable. Compliance standards explicitly require permanent removal, not cosmetic hiding.
- Document your classification and controls. Regulators and plaintiffs' attorneys will ask: did you know this was sensitive data, and what did you do to protect it? An undocumented "we take security seriously" posture won't survive scrutiny. A mapped data inventory, classification decisions, and enforced redaction standards will.
The stakes are straightforward: understanding which types of sensitive information you handle - and treating them accordingly - is the difference between a defensible security posture and a preventable disaster.
Ready to protect sensitive data with permanent redaction? Redactable's AI-powered platform delivers 98% time savings compared to manual redaction, with guaranteed metadata removal and compliance-ready redaction certificates. Start your free trial or schedule a demo to see how permanent redaction works.
Frequently asked questions
The four core types of sensitive data are: (1) Personally Identifiable Information (PII), including direct and indirect identifiers; (2) Protected Health Information (PHI) and health data under HIPAA and GDPR; (3) Payment Card Industry (PCI) cardholder data and financial information; and (4) Confidential business data, including trade secrets, credentials, and restricted operational information. Each type carries different legal obligations and requires specific technical controls.
NIST explicitly states that "all PII is not created equal." Ordinary PII (business contact information, general demographics) poses low to moderate risk if exposed. Sensitive PII (Social Security numbers, biometric data, government IDs, detailed behavioral profiles) poses high risk, including identity theft, fraud, and physical danger. Sensitive PII requires encryption, strict access controls, and permanent redaction before any external disclosure.
Visual redaction with black boxes or blurred text doesn't remove sensitive data from the file - it only hides it. The underlying text often remains searchable and copyable. PDF metadata preserves author information, revision history, and editing details. Hidden layers, transparent objects, and content outside page boundaries can leak sensitive information. NIST, HIPAA, and GDPR standards explicitly require permanent removal of sensitive data, not cosmetic masking.
Access control limits who can see data within your systems. Redaction permanently removes sensitive elements from documents that must be shared externally or preserved for legal reasons. Redaction becomes required when: (1) responding to FOIA requests or subject access requests, (2) producing documents in litigation discovery, (3) sharing research datasets, (4) releasing medical records to third parties under HIPAA, (5) providing audit evidence containing sensitive operational data. Access controls alone fail when documents leave your environment.
Consequences depend on the data type and applicable law. HIPAA violations can reach $1.5 million per violation category annually. PCI DSS non-compliance results in fines of $5,000 to $100,000 per month and potential loss of payment processing ability. GDPR violations can reach €20 million or 4% of global annual revenue, whichever is higher. Trade secret mishandling can eliminate legal protection permanently. Beyond fines, expect breach notification costs, legal fees, reputation damage, and class-action exposure.
More About
Data Privacy



Start Redacting Instantly

No credit card required
Start redacting for free
Cancel any time
Over 98% time savings with AI-powered redaction